OCR
Gescannten Seiten können in durchsuchbaren Text umgewandelt werden, der unsichtbar im PDF gespeichert wird, wenn es gespeichert wird. Dies ermöglicht es den Lesern des PDFs, das PDF nach dem Text zu durchsuchen und den konvertierten Text zu kopieren und einzufügen. pdfMachine verwendet optische Zeichenerkennungstechnologie (OCR), um die gescannten Seiten in Text umzuwandeln. Die Umwandlung in Text durch OCR ist nicht 100% genau. pdfMachine ermöglicht Ihnen die Auswahl der Sprache, auf die Sie OCR anwenden.
OCR kann durchgeführt werden :
- Automatisch von pdfScanMachine nach dem Scannen einer Seite.
- Auf Bildern/gescannten Seiten in einem PDF aus pdfMachine.
- Auf Bildern/gescannten Seiten in vorhandenen PDFs von der Befehlszeile aus, ohne Benutzereingabe. Dies ermöglicht die Durchführung von OCR in Batches.
- Automatisch nach dem Drucken zur Erstellung eines PDFs, für PDFs ohne durchsuchbaren Text.
Um eine gescannte Seite in Text umzuwandeln, öffnen Sie sie zuerst in pdfMachine. Sie können pdfScanMachine verwenden, um eine Seite in pdfMachine zu scannen. OCR kann sogar während des Scanvorgangs durchgeführt werden, indem das OCR-Kontrollkästchen im Scandialog aktiviert wird. Sie können jede Seite aus dem Menü "Tools" in pdfMachine OCR verwenden. Wählen Sie im Viewer- oder Bearbeitungsmodus "OCR ausführen (alle Seiten)", um OCR auf allen Seiten auszuführen.
Das erste Mal, wenn Sie OCR von pdfMachine ausführen, müssen Sie die Sprache der Datei auswählen, die Sie konvertieren. Zum Beispiel, wenn Ihre gescannte Seite englischen Text enthält, wählen Sie "Englisch". pdfMachine wird die benötigten Sprachdateien herunterladen und installieren, um die Konvertierung durchzuführen.
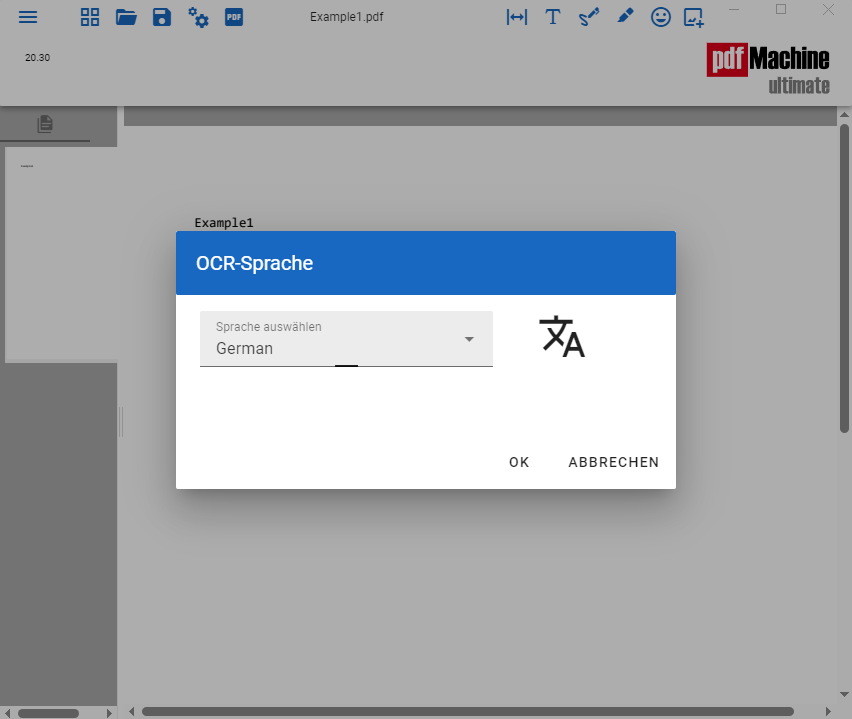
Hinweis: Die Sprachauswahl wird für zukünftige Konvertierungen gespeichert. Die Sprachdateien müssen nicht jedes Mal heruntergeladen werden. Wenn Sie die Sprache ändern möchten, können Sie dies über "OCR-Sprache ändern" im Menü Werkzeuge tun.
pdfMachine wird dann die gescannten Seiten konvertieren.
Führen Sie ein Speichern oder Speichern unter aus, um den unsichtbaren Text mit dem PDF zu speichern.
Der Text ist jetzt von PDF-Readern mit Suchfunktion durchsuchbar. Der Text kann auch kopiert und eingefügt werden.
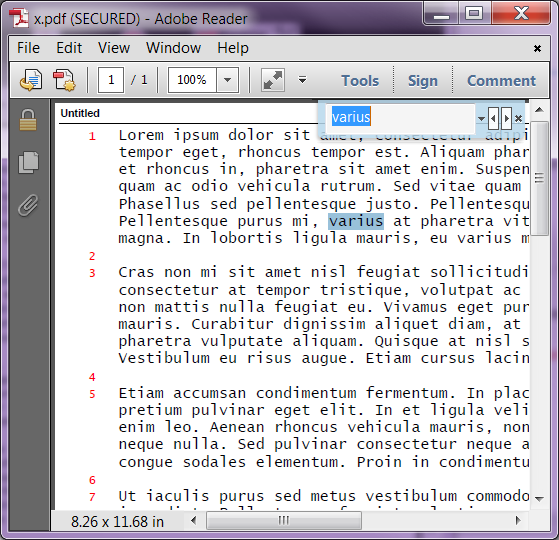
Bei OCR fügt pdfMachine unsichtbaren Text mit dem PDF ein. Der Text ist jetzt von PDF-Readern mit Suchfunktion durchsuchbar. Der Text kann auch kopiert und eingefügt werden.
OCR-Methoden
OCR während des Scanvorgangs
Verwenden Sie pdfScanMachine, um eine Seite in die pdfMachine zu scannen. Aktivieren Sie das OCR-Kontrollkästchen im Scandialog.
OCR aus dem pdfMachine-Werkzeugmenü
Sie können jede Seite über das Menü "Tools" in pdfMachine OCR. Wählen Sie "OCR ausführen (alle Seiten)" aus, um OCR auf allen Seiten durchzuführen.
OCR beim Konvertieren eines Bildes in PDF
Wenn Sie im Windows Explorer das pdfMachine-Kontextmenü mit der rechten Maustaste verwenden, um ein Bild in PDF zu konvertieren, können Sie das Kästchen für OCR aktivieren, um das konvertierte Bild ebenfalls zu OCR.
OCR von der Kommandozeile
OCR kann mit dem pdfMachine-Kommandozeilen-Tool pdfMachineOCR durchgeführt werden. Dies ermöglicht es, OCR stapelweise durchzuführen.
OCR nach jedem Druck, um PDF zu erstellen
Im Bereich "Next Action" der Optionen von pdfMachine können Sie so konfigurieren, dass pdfMachine nach dem Drucken OCR durchführt, um ein PDF zu erstellen, für PDFs, die keinen durchsuchbaren Text enthalten.
Sprachauswahl
Beim allerersten Mal, wenn Sie OCR aus pdfMachine ausführen, müssen Sie die Sprache der Datei auswählen, aus der Sie konvertieren. pdfMachine wird die benötigten Sprachdateien herunterladen und installieren, um die Konvertierung durchzuführen. Die Sprachauswahl wird für zukünftige Konvertierungen gespeichert. Sie können sie auch über das Menü "Tools" ändern.